个人理解:
使用 集成 多个学生网络 来预测 经过在其他数据集预训练的老师网络,通过这种所谓的 预测不确定性 ,各学生网络 针对同一张图片【图片中的各个patch p(r,c)】 老师的输出作为 回归目标;此时 学生网络的预测不确定性和回归的误差 就作为了异常分数;
进一步,为了得到一个 能够输出 discriminative embeddings 的老师网络,作者使用了 两种方法来实现这一效果:
-
蒸馏一个效率低但性能强大的 分类网络 知识,这里面涉及到的一个损失 L_k
-
自监督 metric learning techniques,使用了一种 三重学习 triplet learning ,具体做法是,{p,p+,p-} 三个patch 作为一组,In-triplet hard negative mining with anchor swap [37] is used as a loss function for learning an embedding sensitive to the ℓ2 metric,涉及到第二个损失, L_m

这里面就是一组patch 中 老师网络输出的距离,并取一个最大值
最后又做了一个 描述符 紧凑 descriptor compactness,最小化一个minibatch中描述符的相关性,【感觉类似于 矩阵里面的最大无关组】得到第三个损失
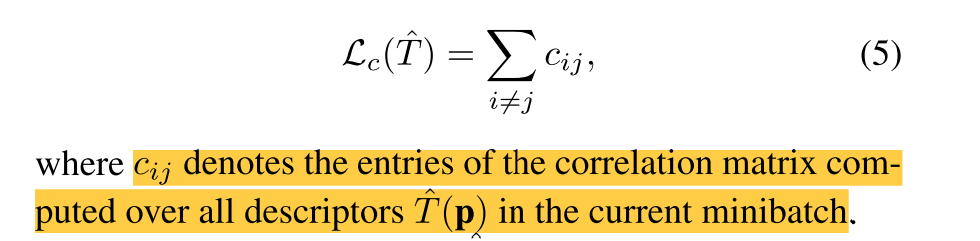
最后的老师网络整体损失是三者分别加权得到,这样训练后得到一个 $\hat T$ ,然后通过一个 确定性变化得到 T [原文:Fast dense local feature extraction for an entire input image can then be achieved by a deterministic network transformation of Tˆ to T as described in [4].]
对于学生,主要是在这个 预测不确定性 和 回归误差 这两点进行设计 损失函数 指导训练
学生针对 一张图像中的 各p(r,c) 输出局部描述符,这些输出被建模为一个高斯分布,然后用这个高斯分布 的均值和方差来 衡量与老师输出的 距离 ,作为每个学生网络的损失函数

然后就是构造了一个异常得分函数,分为两个部分
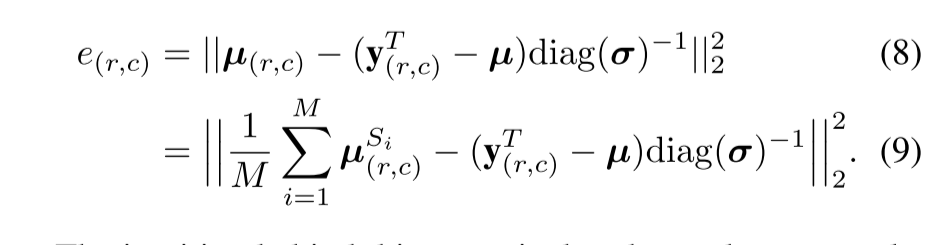
所有学生网络输出建模的高斯分布的均值和方差 与老师网络的输出 距离,也即 回归误差
第二部分就是衡量 这种预测的不确定性 [原文:we compute for each pixel the predictive uncertainty of the Gaussian mixture as defined by Kendall et al. [14], assuming that the student networks generalize similarly for anomaly-free regions and differently in regions that contain novel information unseen during training:],通过 均值 这一指标来计算
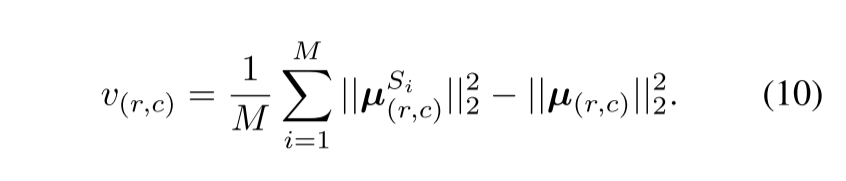
为了将二者进行结合,又分别计算了 均值和标准差 进行规范化,最终二者相加得到 异常评分
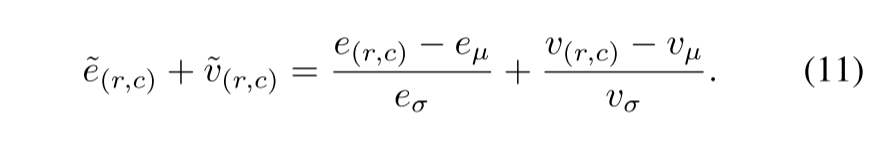
Abstract
我们引入了一个强大的学生-老师框架用于 无监督异常检测和像素级精准异常分割在高分辨图像的 挑战。
学生网络被训练去回归 一个descriptive的老师网络的输出,其被预训练在一个 大型的 来自自然图像 的 patch 数据集。这就避免了先前对数据注释的需要
当学生网络和老师网络的输出有差异时,异常被检测到。这种情况发生在 他们未能泛化 在无异常训练数据 。
这种学生网络的内在不确定性被用做 为一种额外的打分表示异常的函数。
我们对比了我们的方法和大量的现存的用于无监督学习异常检测的深度学习方法 。
我们的实验展示了在大量数据集上超过现有 SOTA 方法的改进,包括 最近引入的 MVTec AD 这一专门设计作为异常分割算法基准的 数据集
Introduction
在众多的计算机视觉领域,无监督的像素精准分割 ,针对区域出现异常或新出现的 对于一个机器学习模型是一个重要的具有挑战性的任务。
在自动化的工业检测场景中,经常在一个单类无异常的数据上训练模型,在推理的过程中去分割有缺陷的区域
在主动学习的设置中,被当前模型检测到的未知区域可以被包括在训练集中去提高模型的性能。
最近,针对一类或多类分类的异常检测被不断改进。
然而,这些算法认为,异常表示自己以一种完全不同的图像形式,并且一个简单的二值化图像级决策 是否是 异常的 必须要做出。
几乎没有工作直接开发面向分割异常区域的方法,这些异常区域与训练数据只有非常细微的不同
Bergmann等人,提供了几个sota算法的基准,并且确定了一个很大的改进空间
现有的工作主要关注 生成类算法 如 GANs或者VAEs。
这些方法检测异常使用 逐像素的重建错误 或者 通过评估 来自模型概率分布的密度;由于不精确的重建或者 poorly calibrated likelihoods,这已被证明是有问题的。
许多监督学习的计算机视觉算法性能被迁移学习进行了改进,通过使用来自预训练网络的discriminative embeddings 判别嵌入。
对于无监督的异常检测,这些方法还没有得到深入的研究。最近的工作表明,这些特征空间可以泛化得很好用于异常检测,甚至简单的 baseline 都优于生成类学习方法。
然而 现有方法在大型的高分辨率图像数据集上的性能受到了浅层机器学习 pipeline的 阻碍,需要进行一个 对所使用的特征空间的降维。
此外,优于他们的容量不足以支撑建模具有大量训练样板的高度复杂的数据分布,非常依赖训练数据的下采样
我们 通过使用一种S-T方法,隐式地建模训练特征的分布 避免这些浅层模型的限制。这使得深度神经网络的高容量和帧异常检测 作为一个特征回归问题。
假设一个描述性特征提取器预训练在一个 大型的来自自然图像的Patch数据集上(teacher 网络),我们训练了一个集成的学习网络在无异常训练数据上 去模仿 老师的输出。
在推理阶段,学生的预测不确定性和对于老师的回归误差被结合起来产生一个dense 异常分数对于每一个输入像素.
我们的直觉是学生在无异常的训练图像集合之外 泛化很差,并且会开始做出错误的预测。

图1展示出来我们方法的量化结果
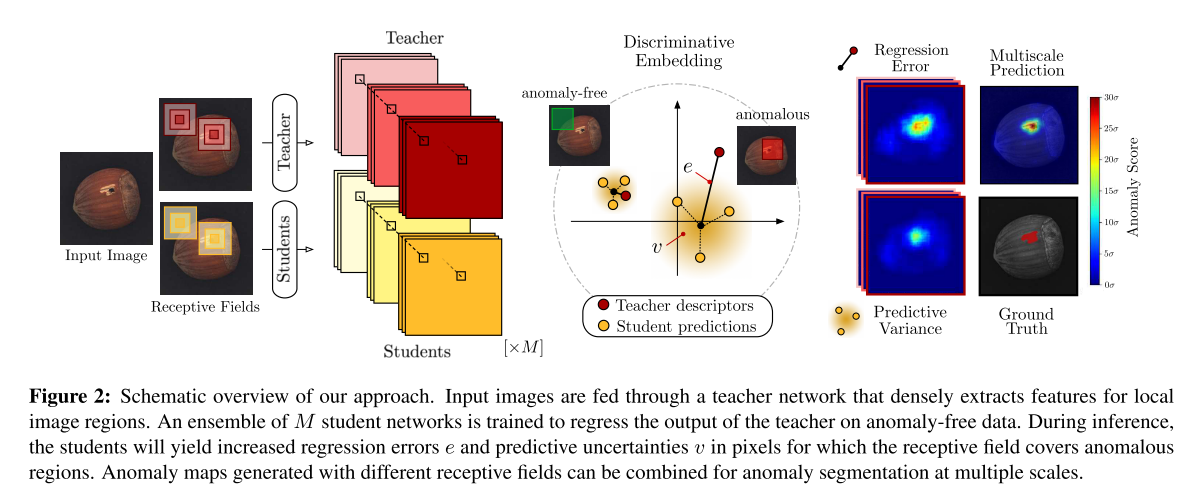
图2给出了整个异常检测过程的示意图
我们的贡献如下:
- 我们提出了一个novel的框架用于无监督的异常检测基于 student-teacher learning。来自一个预训练网络的局部描述符 可以作为整个学生群体的代理标签;我们的模型可以端到端地在大型无标记的图像数据集上进行训练,充分利用所有可用的数据。
- 我们引入了 评分函数 基于 学生们的 预测方差和回归误差来获得dense的异常图 去分割自然图像中的异常区域。我们描述了如何通过调整 学生们和老师们的 感受野来扩展我们的方法区进行多尺度的异常分割
- 我们展示了在3个真实视觉数据集上的 SOTA 性能,我们将我们的方法和许多浅层的机器学习分类器和深层的生成模型 ,这些模型适合教师的特征分布;我们还将其与最近引入的基于深度学习的无监督异常分割方法进行了比较。
Related Work
关于异常检测的文献比较丰富。基于深度学习的异常分割方法强strongly关注生成模型,如自动编码器[1,8]或GANs[32]。它们试图从零开始学习表示,不利用关于自然图像本质的先验知识,并通过在像素空间中比较输入图像和重建图像来分割异常。由于简单的逐像素比较或不完美的重构[8],这可能会导致异常检测性能低下。
Anomaly Detection with Pretrained Networks
通过对无异常训练数据特征拟合浅层机器学习模型,将预训练网络的判别嵌入向量转移到异常检测任务中,取得了较好的结果。Andrews等人的[3]使用来自预训练VGG网络不同层的激活,并用ν-SVM对无异常训练分布进行建模。however,它们仅仅将他们的方法应用在图像分类,并没有考虑异常区域的分割。Burlina et al.[10]也做过类似的实验。他们报告了与从生成模型获得的特征空间相比,discriminative embeddings 区别性嵌入的性能优越。
Nazare等人的[24]研究了不同现成的特征提取器在一个图像分类任务上的性能,用于分割监视视频中的异常。他们的方法训练1-NearestNeighbor (1-NN)分类器,从大量无异常训练补丁中提取嵌入向量。在训练浅层分类器之前,使用主成分分析(PCA)降低网络激活的维数。在推理过程中,为了获得空间异常图,分类器必须对大量重叠的patch进行评估,这很快成为性能瓶颈,导致异常图相当粗糙。
类似地,Napoletano等人[23]从预训练的ResNet-18中提取大量裁剪训练patch的激活度,并使用K-Means聚类对其分布进行建模,然后用PCA进行先验降维。他们还在推理过程中对测试图像进行跨步评估。
这两种方法都是从输入图像中采样训练补丁,因此没有利用所有可能的训练特征。这是必要的,因为在他们的框架中,特征提取的计算成本很高,因为使用了非常深的网络,每个patch只输出一个描述符。此外,由于采用浅层模型来学习无异常patch的特征分布,可用的训练信息必定会被减少。[the available training information must be strongly reduced]
为了避免裁剪小块的需要并加快特征提取的速度,Sabokrou等人以全卷积的方式从预训练AlexNet的早期特征图中提取描述符,并将单峰高斯分布拟合到所有可用的无异常图像训练向量上。尽管特征提取在其框架中更有效,但共用层导致输入图像的采样下降。这强烈地降低了最终异常图的分辨率,特别是当使用具有更大接收域的更深层网络层的描述特征时。此外,随着问题复杂度的提高,单模态高斯分布将无法对训练特征分布进行建模。
Open-Set Recognition with Uncertainty Estimates
我们的工作从最近在图像分类或语义分割等监督设置中的开放集识别的成功中获得了一些灵感,其中,深度神经网络的不确定性估计已被用于使用MC Dropout[14]或深度集合[19]检测非分布输入。Seeboeck等人的[33]证明了用MC Dropout训练的分割网络的不确定性可以用来检测视网膜OCT图像中的异常。Beluch等人[6]表明,在图像分类任务上训练的网络集合的方差是主动学习的有效获取函数。在当前模型中出现异常的输入被添加到训练集中,以快速增强其性能。
然而,这类算法要求领域专家为监督任务预先标记图像,这并不总是可能或可取的。在我们的工作中,我们利用预先训练的网络的特征向量作为学生网络集合的训练的替代标签。然后利用集合输出混合分布的预测方差和回归误差作为评分函数分割测试图像中的异常区域。
Student-Teacher Anomaly Detection
本节描述我们提出的方法的核心原则。给定训练数据集D = {I1, I2,…},我们的目标是创建一个学生网络Si的集合,该集合可以在随后检测测试图像j中的异常。这意味着他们可以为每个像素分配一个分数,表明它与训练数据流形的偏离程度。为此,在大量的自然图像数据集上对描述性教师网络T进行预处理,得到回归目标来训练学生模型。训练完成后,由学生的回归误差和预测方差得到每个图像像素的异常分数。给定输入图像I∈Rw×h×c,其宽度为w,高度为h,通道数为C,集合中的每个学生Si都输出一个特征映射Si(I)∈Rw×h×d。对于行r和列c处的每个输入图像像素,它包含描述符y(r,c)∈Rd,维数d。通过设计,我们限制学生的感受野,使y(r,c)描述I的正方形局部图像区域p(r,c),其边长为p。教师T与学生网络具有相同的网络结构。但它保持不变,对输入图像I的每个像素提取描述性嵌入向量,作为学生训练时的确定性回归目标。
总结:
1.创建的 学生网络集合 为 每一个像素分配一个分数,表明其 偏离训练数据的程度,以此作为检测依据
2.使用自然数据集对 老师网络进行预训练
3.老师在训练数据上的输出,作为各学生网络的回归目标
4.分配的分数是 由学生的回归误差和预测方差 得到
5.学生的输入 $w \times h \times c$ 图像,输出 $w \times h \times d$的特征映射,对于(r,c)位置的像素,有一个 $d$ 维的描述符,
6.对学生的感受野进行设计,使得 (r,c)处的描述符 描述的区域为 $p(r,c)$ 边长为 p
Learning Local Patch Descriptors
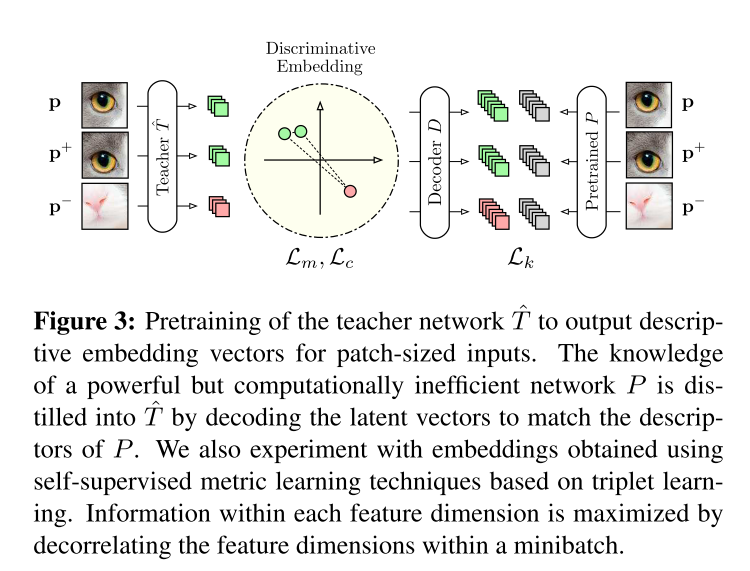
我们首先描述如何使用度量学习和知识蒸馏技术有效地构建描述性教师网络T。在现有的利用预先训练的网络进行异常检测的工作中,对于小块大小的输入或空间上大量下采样的特征映射,特征提取器只能输出单个特征向量[23,30]。相比之下,我们的教师网络T有效地输出了输入图像中每一个边长为p的可能正方形的描述符。T是通过首先训练一个网络Tˆ,将patch大小的图像p∈Rp×p×C嵌入到维数为d的度量空间中,只使用卷积和最大池化层得到的。然后对整个输入图像进行Tˆ到T的确定性网络变换,实现快速密集的局部特征提取,如[4]所述。与之前引入的执行基于补丁的跨步评估的方法相比,这产生了显著的加速。为了让Tˆ输出语义强的描述符,我们研究了自监督度量学习技术,以及从描述性强但计算效率低的预训练网络中提取知识。任意图像数据库中任意作物都可以获得大量的训练patch p。在这里,我们使用ImageNet[18]。
总结:
- 训练$\hat T$,使用 卷积核最大池化 将$p \times p \times c$ 的patch 嵌入到 $d$ 维空间
- 通过一个确定性变换 deterministic network transformation 将 $\hat T$ 变到 T,依据[4]
- 变换后的 T 可以实现 fast dense feature extraction
- 为了 让 $\hat T$ 输出语义强的描述符,调研了两种方法
- 自监督 metric learning techniques
- 从描述性强但计算效率低的网络中蒸馏知识
- patch 可以来自任意数据集,这里使用的是 ImageNet
知识蒸馏 在使用浅层机器学习模型对其分布进行建模时,从图像分类任务训练的cnn的深层获取的Patch描述符可以很好地进行异常检测[23,24]。然而,这种cnn的体系结构通常非常复杂,对于提取局部patch描述符的计算效率非常低。因此,通过将P的输出与从ˆT获得的描述符的译码版本进行匹配,我们将一个强大的预训练网络P的知识提取为ˆT:
$$
L_k(\hat T) = || D(\hat T(p)) -P(p)||^2
$$
D表示全连接网络,将ˆT的D维输出解码为预训练网络描述符的输出维。
总结:将更强的 一个CNN,P 进行蒸馏,将T的描述符通过 全连接层 和 P的输出维度对齐,然后二者之间的差异 作为损失,指导蒸馏的过程。
Metric Learning 如果由于某种原因,预先训练的网络不可用,也可以用完全自监督的方式[12]学习局部图像描述符。在这里,我们研究了使用三重学习triplet learning获得的区别性嵌入的性能。对于每个随机裁剪的patch p,一个三组patch (p, p+, p−)被增广。positive patch p+ 是通过p周围的小的随机平移,图像亮度的变化,加上高斯噪声得到的。negative patch p- 是由随机选择的不同图像的随机裁剪创建的。采用带锚交换[37]的内嵌硬负挖掘作为损失函数,学习对ℓ2度量值的嵌入敏感
$$
L_m(\hat T) = max {0, \delta + \delta^+ - \delta^- }
$$
其中,δ > 0表示边际参数,三重态内距离δ+和δ−定义为:
$$
\delta^+ = || \hat T(p) - \hat T(p^+)||^2 \
\delta^- = min{|| \hat T(p) - \hat T(p^-)||^2 \ , || \hat T(p^+) - \hat T(p^-)||^2 }
$$
Descriptor Compactness 根据Vassileios et al.[35]的建议,我们将一个小批量输入p内的描述符之间的相关性最小化,以增加描述符的紧凑性,消除不必要的冗余:
$$
Lc(\hat T) = \sum{i \neq j} c_{ij}
$$
其中cij表示当前小批量中对所有描述符ˆT(p)计算的相关矩阵的条目。
总结:
这里没看懂
$\hat T$ 的最终训练损失为:
$$
L(\hat T) = \lambda_k L_k(\hat T) + \lambda_m L_m(\hat T) + \lambda_cL_c(\hat T)
$$
其中λk、λm、λc≥0为单项顺序的权重。图3总结了教师判别嵌入的整个学习过程。
Ensemble of Student Networks for Deep Anomaly Detection
接下来,我们描述了如何通过训练学生网络Si来预测教师在无异常训练数据下的输出。然后,我们从学生的预测不确定性和回归误差推断的异常分数。首先,计算所有训练描述符上的分量均值µ∈Rd和标准差σ∈Rd的向量进行数据归一化。对数据集d中的每幅图像应用T提取描述符,然后训练m≥1随机初始化的学生网络Si, i∈{1,…,M},与教师t具有相同的网络结构,对于输入图像I,每个学生输出其在以行r和列c为中心的每个局部图像区域p(r,c)的可能回归目标空间上的预测分布。请注意,学生的结构具有有限的p大小的感受野,允许我们仅通过一个单一的前向传递就可以获得每个图像像素的密集预测,不需要实际裁剪补丁p(r,c)
将学生的输出向量建模为一个高斯分布$Pr(y|p_{(r,c)}) = N(y|µ^{Si}{(r,c)}, s)$,协方差s∈r,其中,µSi (r,c)表示Si对(r,c)处像素的预测。令yT (r,c)表示学生将要预测的教师各自的描述符。将每个学生网络的对数似然训练标准L(Si)化简为特征空间的平方ℓ2distance:
$$
L(Si) = \frac 1{wh} \sum{(r,c)} || \mu_{(r,c)}^{si} -(y^T{(r,c)} - \mu) \ diag(\sigma) ^{-1} || ^2_2
$$
其中diag(σ)−1表示用σ的值填充的对角矩阵的逆。
对每个学生进行收敛训练后,通过对集合的预测分布进行同等加权,可以在每个图像像素处获得混合高斯函数。由此,我们可以通过两种方式获得异常度量:首先,我们提出计算混合平均µ(r,c)对教师的代理标签的回归误差:
$$
e{(r,c)} = || \mu{(r,c)} -(y^T_{(r,c)} - \mu) \ diag(\sigma) ^{-1} || ^22 \
= || \frac 1{M} \sum{i=1}^M\mu_{(r,c)}^{si} -(y^T{(r,c)} - \mu) \ diag(\sigma) ^{-1} || ^2_2
$$
这个分数背后的直觉是,由于在训练中没有观察到相应的描述符,学生网络在推理过程中将无法回归到教师在异常区域的输出。注意,e(r,c)是非常数偶数forM = 1,其中只训练了一个学生,通过学生和教师网络只进行一次正向传递就可以有效地获得异常分数。
作为异常的第二个度量,我们为每个像素计算Kendall等人定义的高斯混合的预测不确定性,假设学生网络对无异常区域的泛化方式类似,而对包含训练中未见的新信息的区域的泛化方式不同:
$$
u{(r,c)} = \frac 1{M} \sum{i=1}^M ||\mu_{(r,c)}^{s_i}||^22 -||u{(r,c)} || ^22
$$
为了结合这两个得分,我们分别计算所有e(r,c)和v(r,c)的平均值eµ,vµ和标准差eσ, vσ,在一组无异常图像的验证集上。将归一化分数相加,得到最终的异常分数:
$$
\tilde e{(r,c)} + \tilde u{(r,c)} = \frac {e{(r,c) - e{\mu}}}{e{\sigma}} + \frac {u{(r,c) - u{\mu}}}{u_{\sigma}}
$$
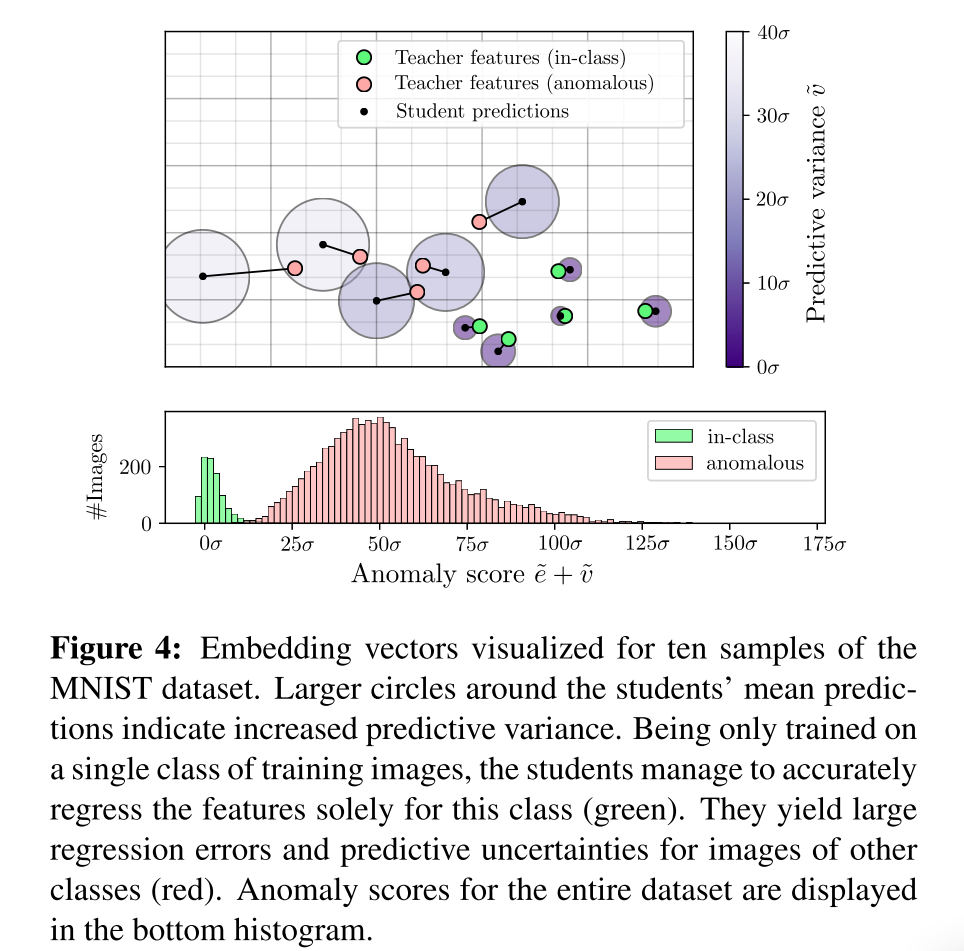
图4展示了我们在MNIST数据集上的异常检测方法的基本原理,将标签为0的图像视为正常类,其他类均视为异常类。由于该数据集的图像非常小,我们使用Tˆ为每幅图像提取一个单一的特征向量,训练一个由M = 5个patchsize学生组成的集合来回归教师的输出。这将为每个输入图像生成一个异常分数。利用多维尺度[9]将特征描述符嵌入到2D中,以保持特征描述符的相对距离。
Multi-Scale Anomaly Segmentation
如果一个异常只覆盖了教师 p大小的感受野的一小部分,则提取的特征向量主要描述局部图像区域的无异常特征。因此,学生可以很好地预测描述符,从而降低异常检测性能。可以通过对输入图像进行下采样来解决这个问题。然而,这将导致输出异常图的分辨率出现不希望看到的损失。我们的框架允许显式控制学生和教师的感受野p的大小。因此,我们可以通过训练多个p值不同的学生-教师集合对来检测不同尺度上的异常。在每个尺度上,将计算出与输入图像相同大小的异常图。给定L具有不同接收域的学生-教师集合对,每个尺度L的归一化异常分数(e(L) (r,c))和(v(L) (r,c))可以通过简单平均的方式组合:
$$
\frac 1L \sum{l=1}^L(\tilde e^{(l)}{(r,c)} + \tilde u^{(l)}_{(r,c)})
$$
Experiments
略
Conclusion
我们已经提出了一个 novel的框架用于无监督的异常分割在自然图像中 这一挑战。
异常得分 来自于 由集成的学生网络的预测方差和回归误差,它们被训练针对 来自一个 descriptive 的老师网络 的 embedding vectors 集成的学生网络 针对 descriptive的老师网络 embedding vectors 进行训练。
集成训练可以端到端进行,完全在无异常的训练数据上进行,无需事前的数据标注。
我们的方法可以很容易地扩展到在多尺度进行异常检测。
我们展示了在大量真实数据集上 超越现有 sota方法的提升 对于 one-class 分类和 异常分割
