公式显示存在一定问题,有些公式渲染不了。
阅读理解
。。。
Abstract
提出了YOLO,相较于之前的工作使用分类器进行检测,YOLO 将 物体检测定义为一个空间分离的边界框 和 相关的类比概率 回归问题。YOLO可以直接在对图像进行异常评估后得到这些数据。然后说YOLO 是一个单一网络,速度非常快,可以进行端到端的优化。实现了一个更小版本的fast yolo,与最先进的比 ,会出现更多定位错误,但不太可能在背景上预测假阳性。最后YOLO学习到了物体的普遍表示,当应用于其他领域,也优于一些现有方法。
Introduction
1介绍YOLO的思想模拟人看到物体,并描述了未来的潜力
2介绍当前的检测系统是如何做物体检测,利用一个分类器,使用滑动窗口在图像上获取子图 然后分类
3介绍了最近的方法,以R-CNN 为例,其使用区域生成方法,首先生成潜在的边界框在图像上,然后在这些边界框上运行 分类器 进行分类,分类完成后使用后续处理来细化边界框 消除重复检测。然后根据场景中其他物体重新给边界框打分【????】。这种复杂的管道是慢的且难以优化,因为每一个组件都要单独训练。
4-8 提出YOLO,非常简单 直接从图像像素 到 边界框定位和类比可能性,只需对图像进行一次处理。介绍YOLO工作过程,一个单独的卷积网络同时预测多个边界框和类比概率,YOLO训练在全部图片,并直接优化检测性能,这种统一的模型相较于传统目标检测具有几种优点。
第一 YOLO是非常快的 可以实时处理视频流。
第二 进行预测时对图像全局进行推理。不同于 基于滑动窗口 和 区域生成的技术,YOLO 看到整张照片在训练和测试时,它隐式的对类比和外观语境信息进行了编码。最厉害的Fast R-CNN 在背景块上经常犯错,是因为它无法看到更大的语境,YOLO在背景上犯错情况少于Fast R-CNN 犯错一半。
第三 YOLO学习了泛化的物体表示,当在自然图像训练,在艺术品上测试,YOLO仍能在性能上高于 最好的检测方法像DPM 和 R-CNN,YOLO是高度泛化的,在被用于其他新领域依然不会挂
9 说YOLO在精度上仍然落后于最好的检测系统,虽然它可以快速识别图像中物体,但很难精确定位一些物体,特别是小物体,在实验中对这一因素进行了进一步研究
Unifed Detection
我们将目标检测的分离组件统一进一个单独的神经网络。网络使用来自整个图像的特征来预测每一个边界框。同时预测所有所有预测框的类比。这以外着我们的网络对整个图像和图像中的物体进行全局推理。这种设计使得可以进行端到端训练,达到实时速度,在保持高评价精度时。
YOLO将输入分为 SxS 网格,如果物体中心落入网格中,那么这个网格就负责对那个物体进行检测。
每一个网格预测 B 个 边界框 和对应每一个框的置信度,这写置信度得分反映了模型对于这个边界框含有物体的信心,以及对预测边界框的准确性。我们定义置信度为 $Pr(Object) * IOU_{pred}^{truth}$. 如果没有目标存在网格中,置信度得分为0。否则,我们希望置信度得分等于预测框和真实框的交并比。
每一个边界框包含5个预测参数:$x,y,w,h,置信度$,x,y 坐标表示了框的中心相对于网格边界,宽度和高度是相对于整张图片。置信度预测表示了在预测框和任何真实框的重叠程度
每一个网格 也输出 C 条件类概率 $Pr(Class_i|Object)$ 这些概率是以网格含有物体为条件的。我们预测一个类概率的集合对应每一个网格,不针对框的数量。
在测试时,我们将类别概率和边界框置信度进行相乘
$$
Pr(Classsi|Object)Pr(Object)IOU{pred}^{truth} = Pr(Classi)*IOU^{truth}{pred}
$$
最终这些 预测 被编码为 $S \times S \times(B*5+C)$ tensor
YOLO 在VOC上设置 S=7 B=2 C=20 所以 7x7x30 tensor
2.1 Network Design
我们实现这个模型,使用卷积神经网络,提取图像特征,全连接层预测输出可能性和坐标。模型网络受到 GooLeNet 启发,网络有24个卷积层 然后接两个 2个全连接层。相较于GooLeNet 使用的 Inception 模块,我们只是使用了 1x1 reduction 层 后接 3x3 卷积层。网络结构如下
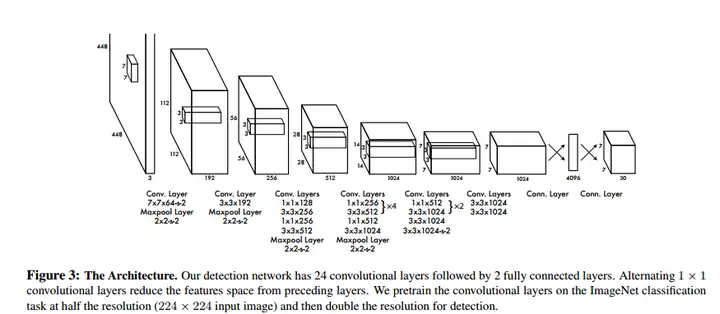
我们也训练了一个快速版本的YOLO 用来推进 快速目标检测的边界。Fast YOLO 使用具有更少卷积层的网络 只有9层,更少的卷积核。除了网络大小,所有的训练核测试参数与YOLO相同
2.2 Training
在ImageNet对卷积层进行了预训练。对于预训练,使用了最开始的20个卷积层 后接一个 平均池化层 和 全连结层
根据其他人经验 添加了4个卷积层和两个全连接层 随机初始化。检测需要细粒度的视觉信息,将输入分辨率从224x224 增加到 448x448
最后一层预测类概率和边界框的坐标。我们将边界框宽和高基于图像宽高进行了规范化使得他们落于0-1区间。将边界框的坐标,转化为相对于 网格内特定单元位置的偏移量,他们也落于0-1之间
最后一层使用了线性激活函数,其他层使用的是 leaky relu
对模型输出的平方误差进行了优化。使用平方和误差,因为它易于优化,但是它并不完全符合我们最大化平均精度的目标。它将定位误差与可能不理想的分类误差同等加权。此外,在每个图像中,许多网格单元不包含任何对象。这使得那些单元格的“置信度”分数趋向于零,通常会压倒包含对象的单元格的梯度。这可能导致模型不稳定,导致培训在早期出现偏差
为了弥补这一点,我们增加了来自边界框坐标预测的损失,降低那些不喊物体框置信度的损失,使用两个参数来完成$\lambda{coord},\lambda{noobj}$,分别设置他们为 $\lambda{coord}=5,\lambda{noobj}=0.5$
平方和误差也对大框和小框中的误差进行同等加权。我们的误差度量应该反映大盒子中的小偏差不如小盒子中的小偏差重要。为了部分解决这个问题,我们预测边界框宽度和高度的平方根,而不是直接预测宽度和高度
YOLO为每个网格单元预测多个边界框。在训练时,我们只希望一个边界框预测器对每个物体负责。我们指定一个预测器为 "负责,根据哪个预测器和真实框有最高的IOU来预测一个物体。这导致了边界盒预测器之间的特殊化。每个预测器都能更好地预测物体的确定尺寸、长宽比或类别,提高整体召回率。【???????】
最终优化的损失函数
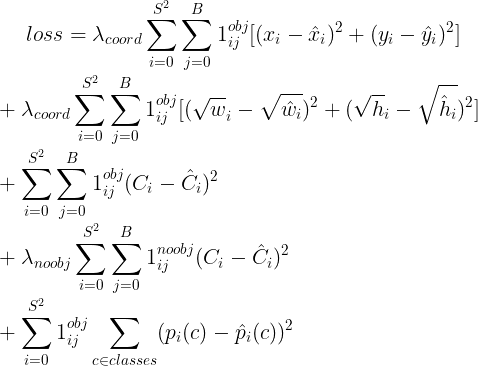
$1{i}^{obj}$ 表示 物体出现在网格i中, $1{ij}^{obj}$ 表示第j个在网格i的边界框 负责预测
损失函数是对 包含物体时分类错误进行惩罚,以及对负责预测的边界框(即具有与真实框最高IOU的那个框)和真实框的坐标误差进行惩罚
后续为 在VOC2007的训练细节 略
2.3 Inference
就像训练一样,仅需要一次网络评估就可输出检测
网格的设计使得在边界框预测中具有空间多样性,对于很明确的一个物体落入网格,网络仅仅预测一个框对于一个物体。然而,有些大型物体,或者物体靠近多个网格的边界 需要被多个网格进行定位,会有多个框产生。使用NMS可以修复这些多的检测框。
2.4 Limitations of YOLO
YOLO在边界框预测上加上了空间约束,由于每一个网格只能预测两个框,只能有一个类。这种空间约束,限制了模型对于临近物体数目的预测,对于那些成组出现的小物体,模型还比较困难。
由于我们的模型学会从数据中预测边界框,它很难推广到新的或不寻常的比例或配置的对象。我们的模型还使用相对粗糙的特征来预测边界框,因为我们的架构具有来自输入图像的多个下采样层。
最后,当我们在近似检测性能的损失函数上训练时,我们的损失函数在小边界框和大边界框中处理错误是相同的。大盒子里的小错误通常是良性的,但小盒子里的小错误对IOU的影响要大得多。我们错误的主要来源是不正确的定位。
Comparison to Other Detection Systems
介绍了其他的检测系统,有
- DFM
- R-CNN
- Other Fast Detectos
- Deep MultiBox
- OverFeat
- MutliGrasp
并结合YOLO进行对比分析
具体内容 略
Experiments
4.1 Comparison to Other Real-Time Systems
和其他实时系统对比,包括DPM,使用VGG-16的YOLO,Fatest DPM 去除选择性搜索使用静态边界框生成 的R-CNN、Fast R-CNN Faster R-CNN
具体评估内容 略
4.2 VOC 2007 Error Analysis
错误分析,针对在VOC数据集上结果 不同的错误类型进行了分析
具体内容 略
4.3 Combing Fast R-CNN and YOLO
YOLO很少在背景上犯错相较于Fast R-CNN,因此通过使用YOLO来消除Faster R-CNN 中的背景错误,得到了性能提升。对于Faster R-CNN预测的每一个框,检查YOLO是否预测了统一框,如果预测了,使用基于YOLO的预测概率和二个框的重叠部分进行改进替换
具体实验数据 略
4.4 VOC 2012 Results
各模型在VOC2012数据集上的结果
评估 略
4.5 泛化性:艺术作品中的人检查
展示了YOLO在毕加索和People-Art数据集上的效果。
其他 略
Real-Time Detection In The Wild
通过接入一个网络摄像头进行了实时检查
其他 略
Conclusion
我们介绍了 YOLO,一种统一的用于目标检测的模型。我们的模型是容易构建的,可以直接从图像进行训练。不同于基于分类器的方法,YOLO是在直接对应于检测性能的损失函数上训练的,而其他是整个模型联合训练。
